AQP++ Connecting Approximate Query Processing With Aggregate Precomputation for Interactive Analytics
摘要
交互型数据分析要求数据库能够在响应时间内响应用户的查询请求。随着数据量的增长,这逐渐成为一个巨大的挑战。
过去主要有两种互相独立的思想来解决这个问题,一种是基于采样的近似查询处理(AQP),另一种是聚合预计算(如data cubes)。
在本篇论文中,我们主张结合两种思想来解决交互型数据分析的问题。我们提出了AQP++,一个使得这种连接成为可能的框架。该框架能够在取样和预计算中取得一个较好的平衡。我们将讨论该种方式的优点和挑战。我们对这些问题以范围查询为例进行了深入的研究,并探索最优的解决办法。我们的实验使用了两套公共的基准以及真实的数据集来证明我们的AQP++非常的灵活以及在预处理、响应时间、以及结果质量上比AQP和AggPre更好。
让二者相结合的思想来源
- 预处理的数据已经在那里,不用白不用
- AQP和AggPre有各自的折中,让两者结合可以提供更灵活的平衡,在预处理开销、查询响应时间以及查询结果的质量上,更好的满足用户的需求。
AQP++的中心思想是:
用取样来估计与已经预计算的聚合结果之间的不同部分。
比如我们想估计如下查询的结果:
 假设下面查询结果已经进行过计算了:
假设下面查询结果已经进行过计算了:
 为了估计q(D),AQP++使用样本来估计去(D)与pre(D)之间不同的部分:
为了估计q(D),AQP++使用样本来估计去(D)与pre(D)之间不同的部分:
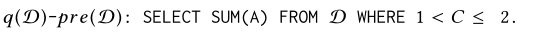 然后将估计值与预计算的值相加,即可得到我们想要的查询结果q(D).
然后将估计值与预计算的值相加,即可得到我们想要的查询结果q(D).
AQP++具有普适性:
- 它支持很多聚合函数(SUM、COUNT、AVG、VAR)
- 可以很容易地扩展来支持许多优化技术,比如分层抽样和外部索引等
- 对于任意聚合查询,AQP能够对其进行无偏估计的话,AQP++也可以。即是说,估计值的期望等于真实值。
为了量化估计结果的不确定性,我们研究了AQP++如何计算置信区间,以及示范了什么时候AQP++能返回一个更小的置信区间。我们将用户查询的和预处理的查询当成两个变量。研究表明,两个变量之间的相关性越强,结果越准确。极端的来说,如果两个查询一样,以为着相关系数为1,AQP++将返回查询的真实解雇。
为了测试AQP++在预处理成本、响应时间、响应质量与AQP、AggPre相比的效果,我们AQP++在范围查询上进行了深入的研究。
研究主要需要解决两个问题:
- Aggregate Identification。 找出和用户查询最接近的预处理的聚合查询。
- Aggregate Precomputation。哪些聚合查询需要进行预计算,在空间成本有限的前提之下。
我们将使用一个简单额例子来阐述这两个challenge。
假设用户想要查询:
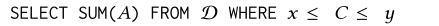
其中x,y=1,2,…,100.一个有效的AggPre方法是计算出一个prefix cube(前缀立方)。在这个例子中,一维的前缀立方包括100个格子:
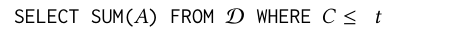
其中t=1,2,…,100.一旦前缀立方建立了,那么任何用户查询都将通过不超过两个格子来计算得到。由于有101*100/2=5050中用户查询,也就说100个格子能包含5050种查询的结果。
让我们首先考虑aggregate-identification问题。假设说,由于空间限制,我们只能存10个格子。在中情景之下,数据立方就只能包含55种聚合的结果。给定一个查询,如:
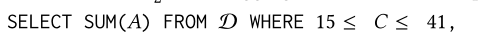 AQP++ 需要知道如下55个已处理的聚合中哪个用来估计用户的查询。
AQP++ 需要知道如下55个已处理的聚合中哪个用来估计用户的查询。
 由于查询结果的质量高度依赖于所选择的最近查询,这个决定必须做的很仔细。我们不可能遍历所有的已处理的聚合值。我们提出了一种非常有效的解决该问题的算法。核心思想是快速识别出长得最像的查询并一一检验是否为最合适的。我们证明了该算法的在特定约束下的优越性以及在通常配置下有较好的实验性能。
由于查询结果的质量高度依赖于所选择的最近查询,这个决定必须做的很仔细。我们不可能遍历所有的已处理的聚合值。我们提出了一种非常有效的解决该问题的算法。核心思想是快速识别出长得最像的查询并一一检验是否为最合适的。我们证明了该算法的在特定约束下的优越性以及在通常配置下有较好的实验性能。
接下来讨论aggregate-precomputation问题。
空间预算一定的情况下,怎么选出应该被预处理的查询。为了解决这个问题,我们发现对分划的选择有两个因素非常的重要,属性相关性和数据的分布。我们首先证明了,如果属性A和C相互独立,且C没有重复值,那么等分划是最优的。这个理论指导我们提出了一个启发式爬坡算法来自动的调整分划的架构基于实际的属性相关性以及数据分布性。
上述示例仅阐述了一维的范围查询的challenge,在多维情况下,将会有更多的Challenge。
总结:
- 主张结合AQP和AggPre
- 深入研究范围查询,并对其中两个主要问题进行建模: aggregate identification and aggregation precomputation.
- 提出了解决的算法。
- 识别出aggregation-precomputation problem两个关键影响因素。
- 我们队AQP++ 用商业化的OLAP系统在三个数据集上进行了评估,实验表明我们在得到精确10倍的结果的同时仅耗费了一个很小的预处理开销。
相关工作
近似查询处理:
基于采样的近似查询处理,关注于分层抽样,还有一些提出基于外部索引的采样。AQP++可以使任意AQP引擎与AggPre相结合。因此所有的这些AQP技术都能拓展到AQP++。
(将AQP++与现有的一些技术进行对比)
- AQP++使用基于全量数据的预计算结果而不是仅一些样本上近似结果
- AQP++使用样本来估计所求回答与预处理的回答间的不同部分而不是使用模型来预测那些为估计的点。
聚合预计算:
数据立方,存下空间中各种可能的聚合结果,被广泛使用在数据仓库之中。
问题建模
这一部分介绍问题建模,为了便于表达我们假设查询没有group by从句。Group by部分的扩展间附录c部分。
定义1 (查询模板)

例如:[SUM(sale),age] 查询产品价格与顾客年龄之间的关系
| 为了便于表示,在后文中我们假设f=SUM并在附录中讨论其它聚合函数之间的拓展。并且,我们假设每个Ci的域为dom(Ci) = {1,2,…,/ | dom(Ci)/ | },并把一个范围查询缩写为SUM(x1:y1,x2:y2,…,xd:yd) |
在AggPre计算中,人们经常计算前缀立方(或其变体)来回答范围查询。
定义2(前缀立方)
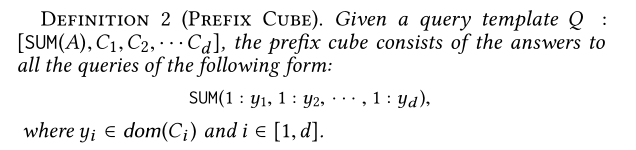
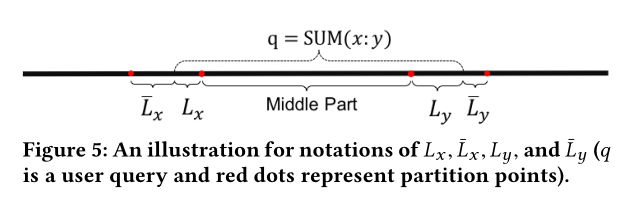
每一个回答被称为立方中的格子。关于P-Cube的一个非常好的性质是,任何一个范围查询Q,它的回答都能用不超过2d个小格子来计算。比如,一个一维查询,SUM(3:5)。该查询的结果可以通过两个小格子获取,比如,SUM(1:5)-SUM(1:2)。对于一个2D的查询,问题的结果能通过最多不超过四个格子得到。如下图所示:
 然而,计算整个P-Cube的代价一般比较昂贵,一共需要计算
然而,计算整个P-Cube的代价一般比较昂贵,一共需要计算
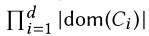 个小格子。因此我们计算一个区块前缀立方,只用包含一小部分格子。
个小格子。因此我们计算一个区块前缀立方,只用包含一小部分格子。
定义3(区块前缀立方)
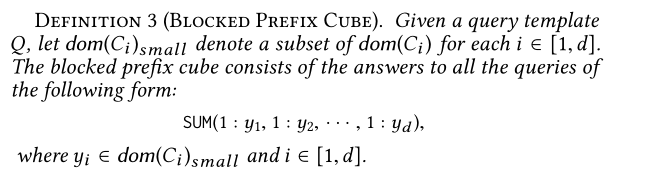 BP-Cube减少了需要预计算的的小格子数。比如考虑一个二维查询Q:[SUM(1),C1,C2],其中dom(C1)={1,2,…,15},dom(C2)={1,2,…,8}.完整的P-Cube包含158=120个小格子, SUM( 1 : y1 , 1 : y2 ) for all y1 ∈ [1 , 15] and y2 ∈ [1 , 8]。 dom(C1 ) small = { 5 , 10 , 15 } and dom(C2 ) small = { 4 , 8 } .那么BP-Cube仅包含32=6个cell。
BP-Cube减少了需要预计算的的小格子数。比如考虑一个二维查询Q:[SUM(1),C1,C2],其中dom(C1)={1,2,…,15},dom(C2)={1,2,…,8}.完整的P-Cube包含158=120个小格子, SUM( 1 : y1 , 1 : y2 ) for all y1 ∈ [1 , 15] and y2 ∈ [1 , 8]。 dom(C1 ) small = { 5 , 10 , 15 } and dom(C2 ) small = { 4 , 8 } .那么BP-Cube仅包含32=6个cell。
Aggregate Identification
接下来开始定义Aggregate Identification问题。令P表示一个BP-Cube,如:
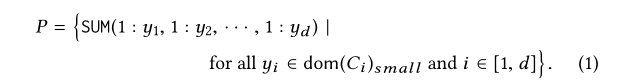
,注意虽然只有P是已知的,由BP-Cube的性质,我们可以假设P+中的所有查询的结果都是已知的。
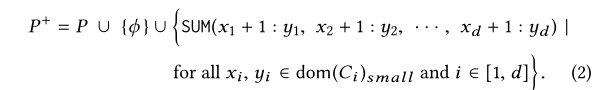
如,令dom(C1 ) small = { 4 , 6 } ,P ={SUM( 1 : 4 ), SUM( 1 : 6 )} , 则 P+ = {SUM( 1 : 4 ), SUM( 1 : 6 ), SUM( 5 :6 ),ϕ} , 其中 SUM( 5 : 6 ) 可以由 SUM( 1 : 6 )−SUM( 1 : 4 )得到,ϕ是一个条件永远为假的空查询.
给定一个用户查询q以及一个样本S,对每个pre ∈P+,AQP++能够返回一个基于某个置信区间的近似值。比如,对q:SUM(1:4).假设AQP++选择了已知的pre:SUM(2:4)并返回了1000+-5(置信概率95%)。这个结果表明查询q的真实结果应该有95%的概率在范围[995,1005]之间。置信区间越大,回答越不精确。因此我们用置信区间的一半定义q对于pre的误差为error(q,pre)。在上述例子中,因为置信区间的宽度是10,那么,error(q,pre)=5.
一旦一个BP-Cube P已知,由于P+中的任意一个值都可以选择用来估计用户查询,我们需要选择出具有最小的查询误差的那个查询。我们将对P的最小查询误差用error(q,P)=minpre∈p+error(q,pre)来表示。
问题1(Aggregate Identification)

考虑一个一维的例子。给定一个用户查询q:SUM(2:5) 以及一个BP-Cube P = {SUM(1:4),SUM(1:6},则有四个已知值在P+中,P+={SUM(1,4),SUM(1:6),SUM( 5 : 6 ),ϕ}。聚合识别问题的关键在于识别出这四个值中最好的用来估计q的答案的值。
Aggregate Precomputation
| 接下来我们将对Aggregate Precomputation问题进行定义。给定空间预算,我们希望找到满足空间预算的最好额BP-Cube。令/ | P/ | 表示一个BP-Cube中cell的数量,令k表示 | P | 的边界阈值。给定阈值k,有许多不同的方式在 | P | <k的前提下来构建一个BP-Cube。例如假设k=6,d=2.那么BP-Cube的组成方式可以是1 × 6, 2 × 3, 3 × 2 or 6 × 1。对于每一种可能的组成方式,比如2 × 3,一个BP-Cube可以通过从dom(C1)中选择2个值,从dom(C2)中选择3个值来实现。 |
为了决定哪种是最好的,我们定义了一个查询模板误差来量化每个BP-Cube的收益并返回查询模板误差最小的那个BP-Cube。给定一个查询模板Q和一个BP-Cube P,因为一个用户可能提出Q中的任意一个查询,我们定义对于P的查询模板误差为 error (Q, P) = max q∈Q error (q, P),表示对所有可能的用户查询中最大的查询误差。我们选取这个误差度量值的原因是因为它对于减少高度不准确的查询的误差更有效,而不是对已知的非常精确的查询结果的那些查询。当然,还有许多其他的方式来定义查询模板误差。在试验中,我们演示了我们的聚合预处理算法,该算法被用于最优化最大误差,该算法也能够有效的减少其他类型的误差,比如平均误差以及中间误差(average error and median error)。
问题2 聚合预计算(Aggregate Precomputation)
 考虑一个一维的例子。给定一个阈值k=2一个查询模板Q: [ SUM(A),C1],其中dom(C 1 ) = { 1 , 2 , · · · , 5 } ,聚合预计算问题在于决定最好的BP-Cube P= {SUM( 1 : t 1 ), SUM( 1 : t 2 )} ,其中t1和t2从dom(C1)中选择从而使得error(Q,P)最小。对于多维的情况,问题将会变得更加具有挑战性,,因为我们需要决定BP-Cube的最佳形状,比如2 × 3 还是 3 × 2.
考虑一个一维的例子。给定一个阈值k=2一个查询模板Q: [ SUM(A),C1],其中dom(C 1 ) = { 1 , 2 , · · · , 5 } ,聚合预计算问题在于决定最好的BP-Cube P= {SUM( 1 : t 1 ), SUM( 1 : t 2 )} ,其中t1和t2从dom(C1)中选择从而使得error(Q,P)最小。对于多维的情况,问题将会变得更加具有挑战性,,因为我们需要决定BP-Cube的最佳形状,比如2 × 3 还是 3 × 2.
从AQP到AQP++
基于取样的AQP
AQP的数学基础是取样和估计理论。
结果估计

f不能是最大值最小值 典型的聚合函数包括 AVG, SUM, COUNT,and VAR。有些自定义的聚合函数也可以较好的支持。
置信区间 在估计结果的同时,AQP经常返回一个置信区间来量化估计结果的不确定性。 计算置信区间的两种方式:
-
分析型,基于中心极限定理.缺少一般性,每个查询有它自己的置信区间。(具体计算看论文)

-
计算一个经验性的置信区间。一般会在原来的样本之上获取一系列的二次样本,然后在二次采样上估计查询结果。获得的结果构成了一个分布,从这个分布中可以计算出置信区间。这是一个更加一般性的方法。计算成本高。
AQP++框架 定制化的结合AQP与AggPre.
AQP++如何估计结果
 先估计ˆ q(S) 再估计ˆ pre(S) ,最后相加。
先估计ˆ q(S) 再估计ˆ pre(S) ,最后相加。


然后带入(4)得到结果
一致性:AQP++用式子(4)把AQP有AggPre结合起来。有趣的是,这个公式表明AQP和AggPre是AQP++的两种特例。
普适性:支持 SUM,COUNT, AVG, and VAR
定理1 对任意聚合函数f,如果AQP能得到下列形式的查询的结果: SELECT f(A) FROM D WHERE Condition ,那么AQP++也可以得到。 证明:见附录A。
定理2 对于任意的聚合函数,如果AQP的估计是无偏的,那么AQP++的估计也是无偏的。
AQP++如何计算置信区间
 经验型类似上面已经介绍的。不过求的是
经验型类似上面已经介绍的。不过求的是
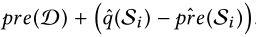 的分布。
关于为什么效果更好,误差更小,置信区间更小
的分布。
关于为什么效果更好,误差更小,置信区间更小
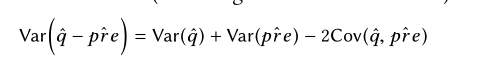
AGGREGATE IDENTIFICATION
我们先给出对一个简化版问题的解法,然后扩展该加法使它更具有一般性。
最优解决办法

暴力破解法:遍历计算 ,成本高
我们的算法,相关系数越高,越好.
SUM( 4 : 10 ) . SUM( 4 : 9 ) and SUM( 1 : 3 )
前一个很相关,后一个明显无关。


定理3
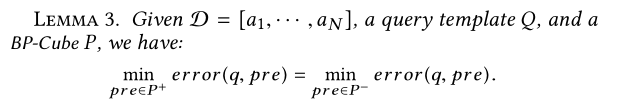
Aggregate-Identification Approach
定理3只在特定情况下成立。
The key idea of our approach is to quickly identify a small number of candidate aggregate values from P + and then examine which one is the best among them.将候选集表示为p-.
公式6展示了一维p-的计算方法。

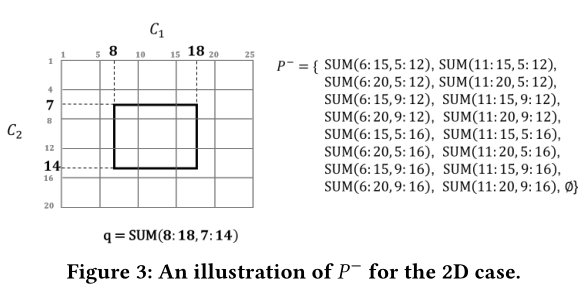
然后遍历P-

AGGREGATE PRECOMPUTATION
两个主要挑战:
- BP-Cube的形状
- 如何选点
一维查询模板 等分划
多维