Continuous Sampling for Online Aggregation Over Multiple Queries
摘要
在这篇论文中,我们提出一个在线聚合系统,叫做COSMOS(Continuous Sampling for Multiple queries in an Online aggregation System),来高效的处理多重聚合查询。在COSMOS中,要先获取一个数据集,从而使对数据集的持续扫描能够对所有的查询的流式随机样本能够提升。此外,COSMOS把查询组织为一个传播图来探索查询之间的依赖关系。用这种方式,更靠近根节点(数据流的来源)的查询集将可能用来计算派生查询的聚合结果。COSMOS使用一些统计学的方法从祖先节点中组合答案来生成一个节点的在线聚合结果。COSMOS同时也提供对未来的可回收的立即查询的分片策略。我们实现了COSMOS系统并在PostgreSQL上开展了扩展性的实验研究。我们在TPC-H标准上的结果表明了COSMOS的效率和有效性。
1、绪论
聚合查询在许多应用中被广泛使用。比如,在在线分析处理中(OLAP Online Analytical Processing)中,存储在数据仓库中的大量数据经常被用来做聚合总结以支持商业分析和决策制定。不幸的是,聚合查询往往需要很高的代价来处理(即是说处理时间很长)并且以前通常在一个阻塞型模型上进行评估,这导致了非常长的初始化时间。
为了处理这些challenge,Hellerstein等人提出了一种非阻塞性的在线聚合机制,即近实时地返回一个近似的结果。与给在线聚合方法连续的生成聚合结果以及对应的置信区间,而不是给用户一个聚合的精确结果。中心思想是不断的从一个数据集中抽取样本,用样本计算一个聚合的近似结果,并在更多样本被选取的同时提升聚合结果的质量。为给用户指明近似值得质量,错误边界和中心区间也同时被计算更新。因为样本数量远小于数据集的数量,所以返回近似结果的成本被缩减了。此外,由于聚合查询主要用于得到大数据集的一个粗糙的概览,可以预料的是用户一旦得到他们质量令他们满意的查询结果,他们就会较早的结束查询过程。因此,查询的处理时间会比计算精准聚合结果的时间小得多。
在这篇论文中,我们研究了如何高效的部署在线聚合来处理多重聚合查询。多重聚合查询有很多种形式。一个简单的复杂查询可能引入多重聚合。举个例子,一个嵌套查询将在内部查询和外部查询中同时引入聚合。另举一例,考虑如下查询(找到特定部门供应商的平均供应数量),这种查询在数据仓库应用中很常见(the lineitem schema is taken from the TPC-H benchmark): SELECT AVG(quantity) FROM (SELECT supp, part, SUM(quantity) as quantity FROM lineitemWHERE part = 10 GROUP BY supp, part);
一个单个用户有很有可能在多重聚合查询中转换。这在OLAP应用中很常见,因为用户可能经常在他或她的数据立方操作中向上或向下操作。最后,不同用户提出的聚合查询可能共享一张数据表。我们注意到在这些查询(和子查询)中存在许多依赖关系,比如,我们能够潜在得获取一个查询(或子查询)的在线聚合结果通过其他的查询(或子查询)的在线聚合结果。此外,我们可以潜在地重复使用可回收的样本来提升一大堆查询(而不是每个查询仅回收它自己的样本)。
我们提出了一个叫COSMOS的在线聚合系统,来高效的处理多重聚合查询。COSMOS有一大堆鲜明的特性。 1. 它随机地抓取一个数据集如此回收自任意地方的元组能被所有的查询作为随机样本。 2. 它连续的扫描抓取的数据集来生成一个样本流。 3. 为了探究查询之间的依赖关系,COSMOS将这些查询组织为传播图,如此靠近根节点的查询将会把他们的估计值反馈给他们祖先查询或依赖查询。这样一个架构能够最小化计算的间接成本。 4. COSMOS对未来的立即查询也提供一个分治策略。 5. 最后,COSMOS使用一些统计学的方法将来自祖先节点的结果组合起来生成一个节点的在线聚合结果。
其他一些工作也提出了连续扫描一个数据集的思想。比如,DataCycle project,整个数据库在高带宽的通信网络上面循环广播,通过一系列的数据过滤器,表现复杂的并行协作搜索操作。最近,George等人提出了CJOIN pipeline,连续的传送元组从一张实际的表到一个大量查询的过滤器序列。我们COSMOS 有着相似的动机,然而,COSMOS循环一个抓取的数据集来产生一个随机样本流。COSMOS与之前的集中架构不同因为它被设计用来做近似查询处理。传播图中的每个节点都是一个查询(这与CJOIN中的以为过滤器不同)并且节点共享聚合结果(而不仅仅是元组)。
我们实现了COSMOS冰鞋在PostgreSQL上用TPC-H标准进行了评估。我们的扩展性能研究表明COSMOS能够很快地收敛出一个很好的近似结果。并且,可以看到它比许多原生的算法更加高效。
这篇论文的剩余部分按下列形式进行组织。在下一部分,我们将给出COSMOS的一个概览。在第三部分,我们将展示我们将查询组织成一个传播图的算法,在第四部分我们展示出我们的在线聚合中使用的统计估计器。第五部分我们说明我们的一个实验研究的成果。第六部分回顾相关工作。最后我们对本篇论文做一个总结。
2、COSMOS:概览
图1说明了COSMOS的系统架构。COSMOS主要有两个组件构成:爬取器和传播图。
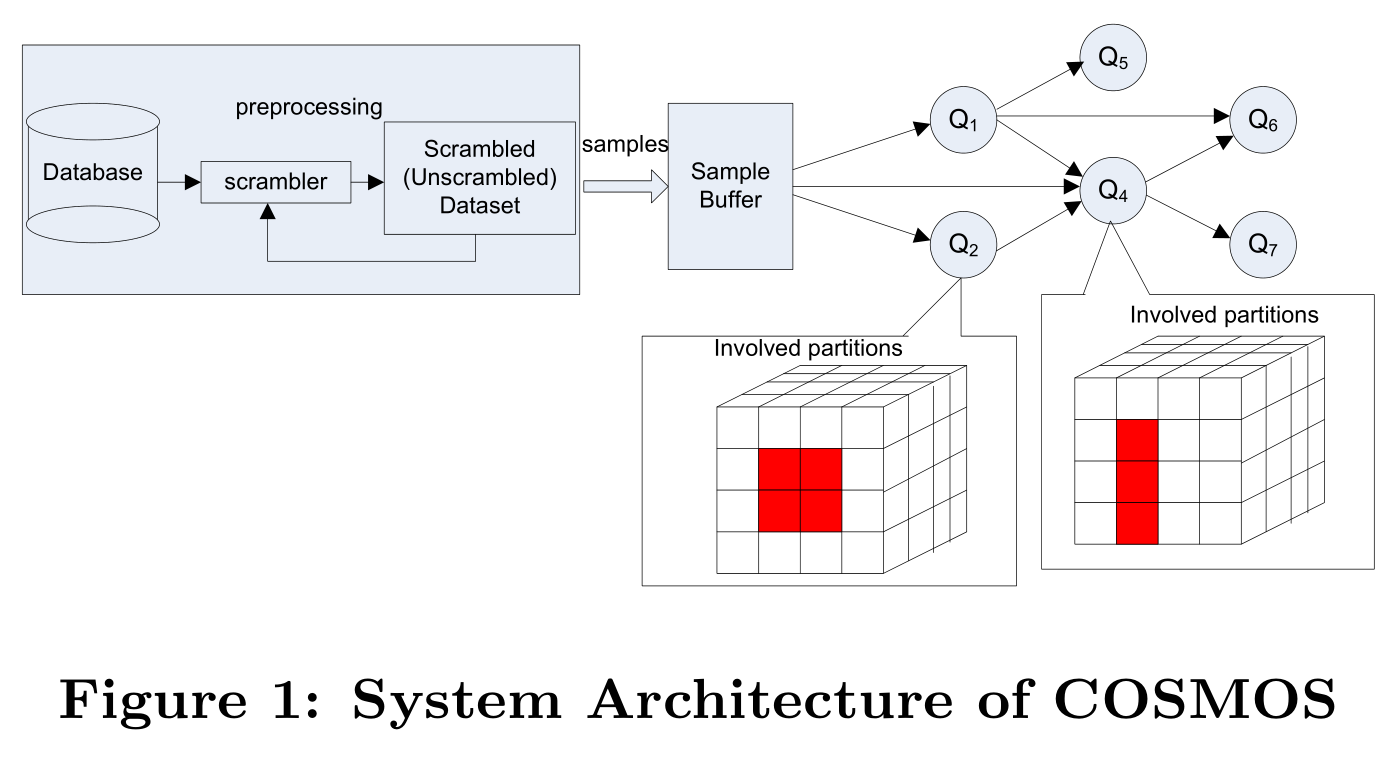
爬取器
给定一个数据集,爬取器的任务就是从数据集中生成一个随机样本流。传统的实现方式是在运行是从数据集中随机的选取样本。然而,我们却提倡把抽取出的随机样本序列存储为一个爬取的数据集。用这种方式,通过扫描爬取集,我们就能够生成一个随机样本流。这种设计来自于一系列的简单而有趣的观察(这也符合这种方法的优点)。首先,我们从原始数据集的一个随机页中获取一个随机样本,尽管我们有一页从爬取数据集的一页中获取的随机样本。其次,我们能有效的消除随机查找,并且能够从爬取数据集中序列扫描获取样本。这意味着取样的I/O成本被大幅度的减少了。事实上,这种“顺序访问数据的收益是巨大的”因为“完全的随机磁盘访问能顺序访问慢五个数量级”。[9]这篇论文中的结果表明随机访问和顺序访问的吞吐量分别是316 values/sec和 53.2M values/sec (这篇研究在一台Windows 2003服务骑上,这台服务器的配置是64GB RAM,8*15000RPM SAS一RAID5配置的磁盘,每条记录的大小是16个字节)。我们自己的初步研究表明顺序地扫描一个100GB数据集的时间大概是1400sec,对应的是随机从数据集中随机取样时间的1.5%。第三,读取k个页面的样本,我们就能拥有大量的样本(比在传统的算法中k个随机页获取k个样本多)。这也就是说错误边界更低以及置信度更高(我们第五部分的实验研究证明了这一点)。从另一个角度来看,这也意味着我们能够在和传统的算法达到相同准确度的同时更快的访问更少的页面,或者在同时访问k个页面的同时得到更高的准确率。 第四,我们连续的在爬取的数据集中循环–当访问到最后一页时,从第一页重新开始。这意味着当一个查询被提交处理时,我们能够为该从任意一页开始进行取样。我们把每个查询读取的第一页作为它自己的抛锚页(anchor page)。一个查询将达到精准答案,如果必要的话,当相同的抛锚页再一次被读取时并且,一个稍晚到达的查询可能能够重新使用(可能还在执行的)稍早查询的结果(而不仅仅是数据样本本身),因此能够比一个更早的抛锚页更早地到达它自己的抛锚页,从而在更短的时间内更好的提高一个估计聚合的准确率。
为了爬取这样一个数据集,我们采用了如下的一个简单的策略:我们顺序地扫描一个文件,当我们扫描每个元组时,我们将把它放置在一个初始化为空的爬取集的一个随机的位置上。爬取集接下来用同种方式继续爬取。上述过程重复许多次。最后,爬取集就可以被用于在线聚合的源数据集了。
对于引入多重关系的查询,对立即结果生成一个随机样本流可能很有必要。基本上,可以使用两种算法。我们可以先预计算join的结果然后再爬取。或者,我们可以在查询的join属性上建立索引从而使用索引嵌套循环join。为了从这两种方式的join中生成一个随机的样本流,我们选取一个关系作外关系R,另一个关系作为内关系S。我们从R中抽取样本就像在单个关系表中那样,顺序扫描爬取集。对每个从R中选取的样本记录,我们检索S的索引。join的输出则构成了两个关系join的随机样本流。第一种架构在存储和效率、准确率之间进行了折中,第二种架构牺牲了效率和准确率来满足灵活性。在数据仓库系统中,大多数查询是主键/外键做join(如TPC-H schema)。我们可以使用第一种架构做抽取。正相反,如果查询是陆陆续续的提交的(if queries are issued on the fly),那么第二种架构比较合适。
在我们的系统中,我们采用了离线批量更新的策略。数据库系统的更新被收集起来然后进行批量处理。在这个过程中,将不会处理查询。如果有一大批的更新需要处理,那么在所有的更新都提交了以后,我们将会重建这个爬取集。此外,对每个新插入的元组t,我们随机地从爬取集中选择一个元组t’并用t代替t’。t’追加到爬取集的最后。
将查询组织成传播图
第二个组件是传播图,是一个有向无环图,其中节点表示查询,两个节点之间的边表示两个查询之间的依赖关系。这种依赖关系使得一个父节点的结果能够被它的子节点所使用。数据源是图的根节点。正如图1所示,从爬取集中读取的数据页首先缓存在一个样本buffer中。缓冲区中的记录接着向查询传播,然后被丢弃这样缓冲区中的空间能够被释放出来然后可以读后面的数据页。
在一中极端情况下,我们可以拥有一个胖的(双层的)传播树,其中所有的查询都仅依赖于源数据流。这对应的情况是所有的查询都不相互依赖。然而,每一个样本的读取都被所有的查询共享。一个典型的传播图能够有机会共享聚合的立即结果,而不仅仅是数据。例如,考虑下面三个查询(使用TPC-Hschema作为示例):

假设查询按如下顺序到达:Q1,Q2,Q3。现在,尽管Q1和Q2共享数据的子集,但是牺牲Q1的结果给Q2也不可能,因为我们只能维护一个对Q1单个的运行时平均值以及错误边界。幸运的是,我们观察到如下:如果我们把基于Q1的结果按照returnflag做分划(例如我们对于不同的returnflag生成运行时均值和错误边界),那么我们就可以循环使用两个分划的输出给Q2(Q1仅需要检查元组的quantity是否≥20以及returnflag是否=“r”or“a”)。像这样,我们如何使用Q2的输出给Q3就很清晰。然而,这个问题,对于Q3就更加复杂因为它能够同时使用Q1和Q2的分划。组合Q1和Q2的分划来生成Q3的结果比较困难。因此,我们需要一个更加侵略性的策略来均衡立即结果。
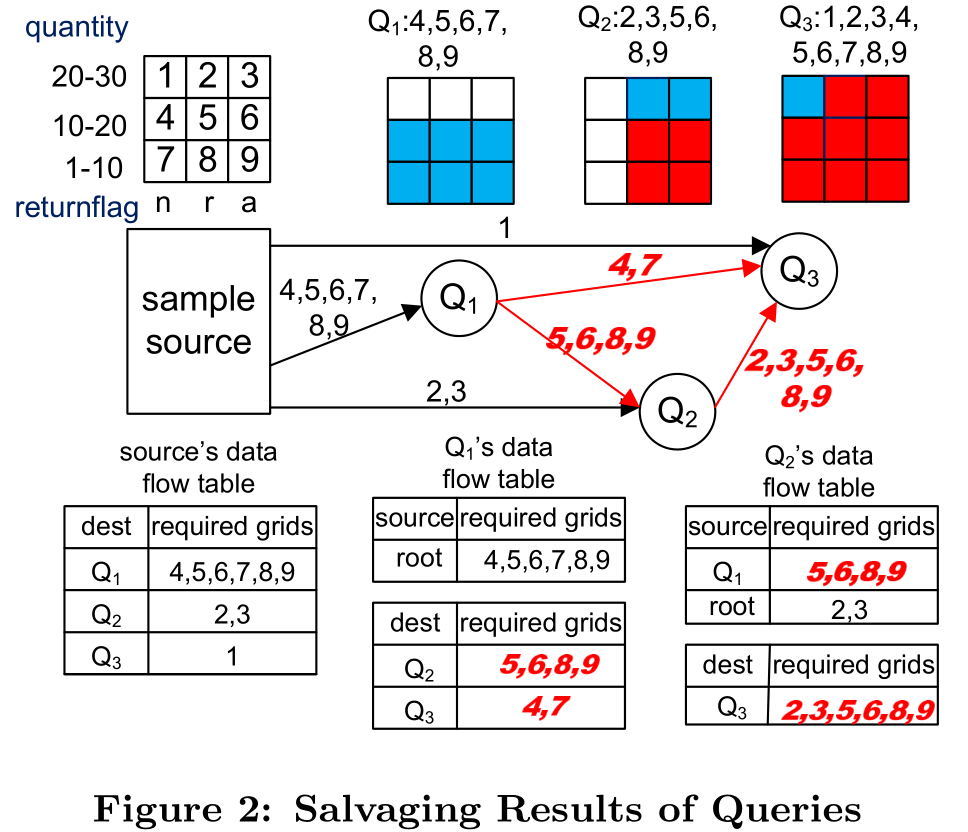
图2展示了一个再利用查询之间的分划的示例。假设表被按照quantity和returnflag分划成了9个小格子。Q2可以再利用对Q1的5,6,8,9的结果,Q3能够利用除第一个格子以外的所有格子的结果。有意思的是,查询的到达顺序能够影响再利用。例如,如果Q3先到达,那么它就可以被分划成同时对Q1和Q2有利的结果。
现在,我们能够识别出我们在传播图设计中的关键challenge。 1. 我们需要决定样本和回答如何被分划。我们的思想是把样本和回答分划成小格子(正如图2所示的那样),然后回收利用包含在一个查询中的小格子。 2. 我们需要一种方式来测量查询之间的依赖关系。基于这种关系,我们能够构建有向无环图来再利用样本回答。然后我们需要随着请求的提交和完成动态的维护该有向无环图。 3. 每个查询的结果都是从可能多个的父节点中提取的(包括数据源)。我们需要使用统计工具来把这些部分回答合并成一个查询答案。 我们将在第三部分讨论前三个issue,在第四部分讨论最后一个issue。
3、传播图
给定一个查询集,我们将其组织为一个数据流图。图中的每一个节点对应一个查询,节点之间通过数据流连接。样本以及部分结果在节点之间通过数据流共享。当一个查询加入到系统中时,它选取某些节点作为它的数据源并通知这些节点它所请求的样本和回答。相应的节点则会为这个新节点生成一个数据流。样本或部分结果之后就会流向这个心得节点,然后就会组成这个新节点自己最终的结果(同时也可能维护一些结果以便再利用)。在这个部分,我们讨论如何建立和维护这个传播图。
基于查询的分划
当一个新的查询加入到系统中时,我们需要评估它与现有的查询之间的关系。特别的是,如果两个查询需要处理一个公共子集的元组,我们就可以让这两个查询共享样本以及部分结果,比如第二部分的查询Q1和Q2。然而,正如提到的那样,Q2能使用Q1结果的前提是Q1需要维护它自己回答的分划。此外,尽管Q1分划了使得Q2能够再利用这些回答,也可能再来一个Q4(如 select avg(discount) from lineitem groupby returnflag, quantity;),且并不能够利用Q1为Q2所做的分划。为了处理这个问题,我们采取了,作为第一次切分,一个直接的解决办法,把数据空间静态的分割成微小的格子来保证回答中包含的格子能够回收利用。
为了将数据空间划分成格子,我们需要识别出分划的候选属性。我们将属性识别成两种类型来作为分划的候选。 类型1是那些出现在“Group By”从句中的属性列。通过对这些属性列的分划,我们可以再利用样本来回答“group by”查询。 第二种类型的数据列是出现在“Where”谓词中的属性列。通过对第二种类型属性的划分,我们能够重利用样本来回答具有不同选择谓词的查询。
对于1-型属性,我们基于分组的名字来分划列,如果分组的数量比Ng小,其中Ng是一个系统预先决定的参数。此外,我们还根据2-型属性来分划列。第2-型属性,我们基于值来划分。在接下来的讨论中,我们关注如何在2-型属性上自适应的分划。一种直接的方法是统一分划空间(例如,对于表的每一列,我们将之均等的分成k个小格子)。不幸的是,这种方式苦于维度的诅咒,一张表有10个分划属性那么每个属性被分成10个范围将会有1010个小格子。小格子的数量可能比元组的数量还多。维护包含部分结果的所有小格子是不切实际的。
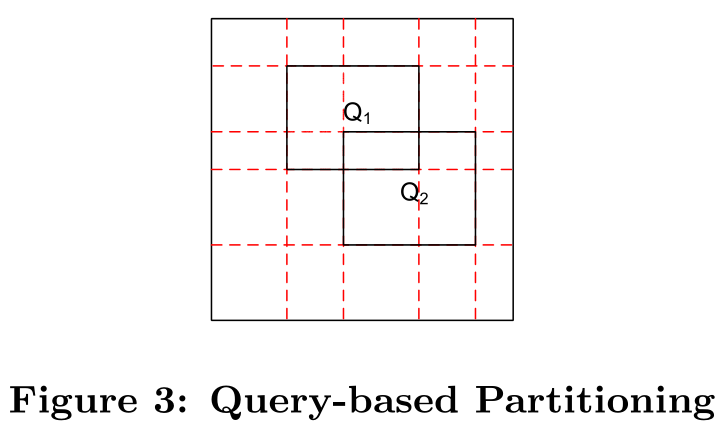
一个可选择的方法,我们称之为Partition,是把空间基于查询的工作量进行分划。一个查询训练集可以收集起来作为工作量的代表。这种架构的思想是对每个查询分划空间使得格子被完整的包含在某些查询中,并且我们能够在查询之间共享这些部分结果。图3阐述了我们的算法的思想。我们基于查询Q1和Q2对空间进行了分划。生成了一个一个5*5的分划,每个查询的搜索范围包括4个格子。Q1和Q2共享一个小格子。这种算法运行表现的非常好,如果搜索条件是有限的。然而,大部分晴朗下,这种算法还是会生成太多的小格子。为了苏建维护成本,我们提出了一种基于查询的自适应的分划架构,QueryPartition,来合并一些分划。
 算法1描述了我们自适应架构算法。Sq是训练集以及pNum是系统设置的分划的最大数量。如果分划的数量小于pNum了,那么我们就可以终结该过程。否则,我们将迭代的执行合并分划。在每个迭代过程中,我们组合一系列的分划。特别的是,对每个分划属性,假设它已经被分割成了k个子范围r1,r2,…,rk。我们试图组合这些连续范围。在相应的分划都被合并以后,我们评估现有分划的利用率。在这个过程中,我们使用了一个简单的利用率度量值–我们简单的计算能被再利用的格子的数量。在每个迭代中格子的数量都在减小并且我们能在格子的数量减小到对应阈值时终止这个过程。
算法1描述了我们自适应架构算法。Sq是训练集以及pNum是系统设置的分划的最大数量。如果分划的数量小于pNum了,那么我们就可以终结该过程。否则,我们将迭代的执行合并分划。在每个迭代过程中,我们组合一系列的分划。特别的是,对每个分划属性,假设它已经被分割成了k个子范围r1,r2,…,rk。我们试图组合这些连续范围。在相应的分划都被合并以后,我们评估现有分划的利用率。在这个过程中,我们使用了一个简单的利用率度量值–我们简单的计算能被再利用的格子的数量。在每个迭代中格子的数量都在减小并且我们能在格子的数量减小到对应阈值时终止这个过程。
传播图
分划空间的目的有两个方面。首先,它使得我们能够轻易的决定一个查询如何分划来对其它查询有益。在图2 中,我们将空间预先分划成了9个小格子(基于两个属性,quantity和returnflag)。当Q1到达是,它组织它的部分回答到6个部分(基于预分划)。第二,它使得我们能够轻易的确定哪些可以被共享。在图2中,当Q2参与进来的时候,它将它的回答组织成6个部分,并且注意到它能够从Q1中再利用4个分划。。
传播图是一个有向无环图(DAG)。每个节点代表一个查询。我们使用Qi来表示节点i或查询Qi。样本流源,用Q0表示,构成了有向无环图的根节点。一条边Qi→Qj表明从Qi到Qj有数据流。特别的是,对于一条从Q0→Qi的边,实际的样本数据是从样本源流向节点Qi的。Qi将基于收集到的样本进行计算分划的聚合结果。如果一个查询只有一个格子的部分(而不是一个完整的格子)参与,那么summary data也会用于计算他们;然而,这样的部分分划将不能够被回收共享。这些样本随后将会被丢弃。注意到一个查询有可能不满足预分划(e.g., a query that groups by discount)。在这种情况之下,这样的一个查询也将从Q0中抽取样本并用于计算它自己的回答。对这些查询,我们目前的解决方式是不提供任何机会来回收他们的回答。需要更侵入式的分享方法,我们计划在未来的工作中讨论这个。
另一方面,对于Qi→Qj(i,j≠0)这样形式的一条边,不需要传输样本集;而是,那些共享的小格子的聚合结果将从Qi传至Qj。参考图2,边上的数量表示数据(样本或部分结果)的小格子需要被传送–正常字体表示实际样本,斜体字表示聚合后的数据。
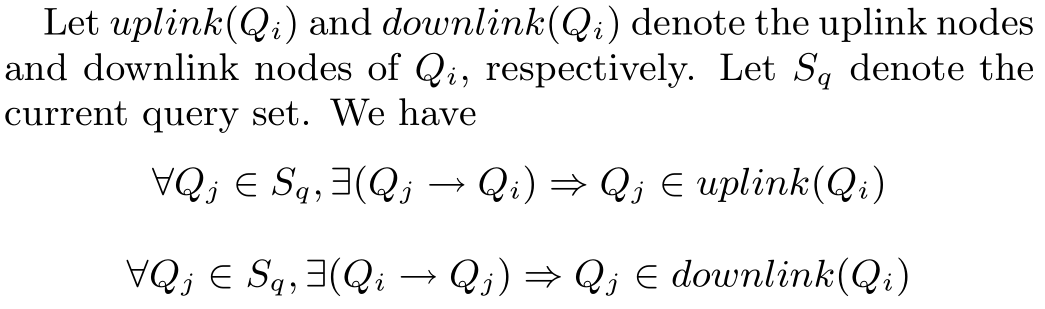
每个查询节点在它的上游注册自己需要的格子。参考图2,在Q1上,我们看到Q2注册了它自己需要的有聚合结果的格子5,6,8,9;Q3注册了它感兴趣的聚合数据格子4和7.我们还可以看到,Q2保留了数据的来源(它从Q1的部分结果中获得了格子5,6,8和9,从根节点上获得了样本数据格子2和3)。传播图中的节点根据下游节点的注册信息来传播样本数据和部分结果。传播图定义了样本如何在查询之间传播。
我们现在可以开始讨论传播图如何构建了。构建一个传播图的中心思想是促进样本的共享。当我们在小格子之间传播样本的时候,两个查询之间的关系也由其涉及的小格子而确定了。一般来说,如果两个查询涉及到相同的小格子,那么我们就能够再利用该小格子的部分聚合结果。对一个特定查询Qi,小格子可以分成以下三种类型。
 对于1-型小格子,Qi需要从数据源(Q0)中提取样本如果不存在它可以回收利用的查询;否则,如果有部分结果可以使用,它就会重利用它。对于2-型小格子,Qi需要从Q0中提取样本来计算它的部分结果,由于该种类型的的小格子的结果不能被Qi使用(因为这些结果是基于从整个小格子空间获取的)。我们使用f1(Qi)和f2(Qi)来分别表示Qi的1-型和2-型小格子的集合。为了简化描述,我们定义函数F如下:
对于1-型小格子,Qi需要从数据源(Q0)中提取样本如果不存在它可以回收利用的查询;否则,如果有部分结果可以使用,它就会重利用它。对于2-型小格子,Qi需要从Q0中提取样本来计算它的部分结果,由于该种类型的的小格子的结果不能被Qi使用(因为这些结果是基于从整个小格子空间获取的)。我们使用f1(Qi)和f2(Qi)来分别表示Qi的1-型和2-型小格子的集合。为了简化描述,我们定义函数F如下:
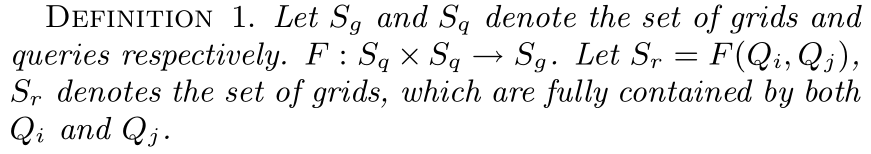
F返回能够在查询之间共享的小格子。很明显,F(Qi,Qj)=F(Qj,Qi)。
令Sq表示系统现有的查询集。当新查询Qi出现在系统中,我们在Sq中搜索查询并将Qi与这些查询联系起来,从而是这些查询的部分结果能够再利用。直观的说就是最大化结果的共享。算法2表明了我们求相关查询的主要思想。首先,按F函数求集合中查询与Qi的公共格子个数并按照倒序排序。如果查询Q1和Q2拥有相同的F值(即F(Q 1 , Q i ) = F(Q 2 , Q i )),Q1的评分将高于Q2当且仅当|f 1 (Q 1 )| < |f 1 (Q 2 )|. 换句话说,我们更偏爱设计更少1-型小格子的查询。然后,我们连续的从列表中提取前面的的查询新来的查询的搜索范围已经被全部覆盖或是候选队列中已经没有查询。当把一个查询插入结果集,我们将重新计算剩余查询的可重用的格子及分数。我们通过删除已经在结果集中的查询的效果来减少查询的分数。我们使用F来计算两个格子集中的公共格子集。


假设算法2找到了对新进查询Qi的集合Sr。Qi将作为Sr中查询的子节点(后代)加入系统。特别的是,对于Sr中的任意查询Qj,我么都添加一条边Qj →Qi 。算法3描述了一个查询节点的加入过程。G表示在Qi中涉及的格子集。我们迭代Sr中的所有查询并添加对应边。当加入边Qj→Qi时,Qi将在注册它需要从Qj提取的格子。最后,如果有些格子不能在已存在的查询集中找到,Qi直接从根节点(数据源中)拉取样本。
从根节点到一个查询的数据流由从数据库中提取的样本组成,而从查询到另一个查询的数据流则由包含部分结果的格子组成。
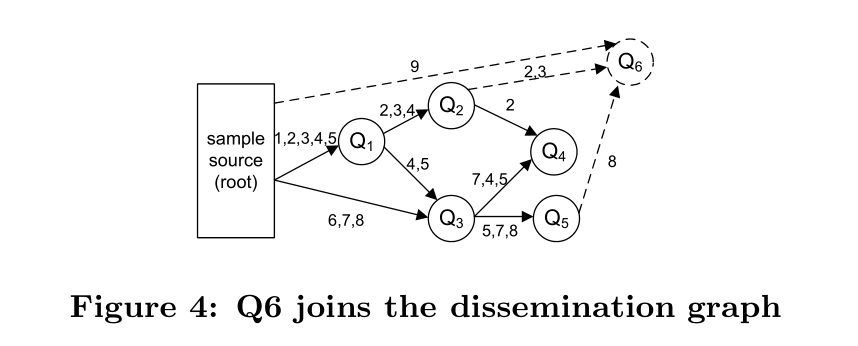
图6描述了将一个新查询加入传播树的过程。在这个例子中,我们假设数据空间已经被分划成了9个小格子(记为1到9)。上图表示了Q1请求从格子1到格子5的样本元组。在Q1上,维护了从格子1到格子5的部分查询结果。Q3请求格子4到8.不过,它能够从Q1中在利用格子4和格子5的聚合结果,但是也需要从数据源获取6-8的样本元组。现在,假设Q6加入到系统中,并且它覆盖了2,3,8,还与格子9有部分重叠。Q6搜索已存在的查询并重利用格子2,3,8的结果。查询Q1,Q2和Q4能够共享他们对格子2的结果。Q2被选取因为它只维护了3个格子的结果因此成本最低。相似的,Q2和Q5倍选取用来提供3和8的结果。由于Q6只是部分覆盖格子9的结果,它将直接从样本源中获取样本。为了提高性能,它继承了来自样本源的对该格子(9)缓冲的样本.
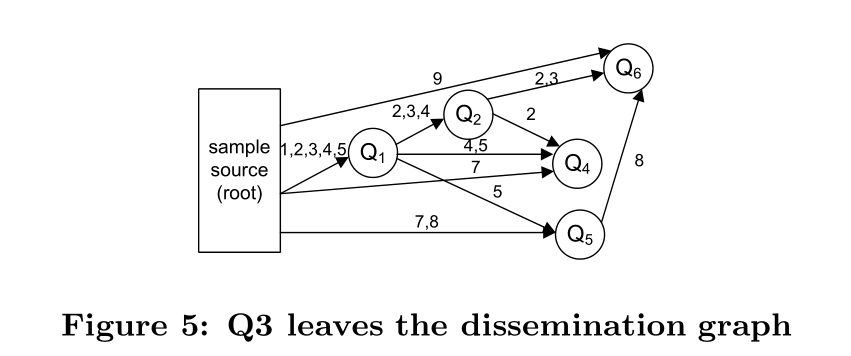
当一个查询终止时,我们需要把它从系统图中移除并重新组织查询节点。假设查询Qi结束了。我们需要移除它在上游节点中注册的信息并重新组织下游节点的查询,因为这些节点对Qi有依赖。算法4描述了查询节点离开系统的处理。对于Qi下游节点中的每个查询Qj,我们为Qj对Qi的上游节点进行排序。然后基于该结果,我们添加查询中的新边。图5描述了查询间的数据流重新组织的一个例子。这里,Q3(图4中)完成了它的处理并离开系统。它的下游节点Q4和Q5需要调整它们的连接。基于算法4,新的数据流图如图5所示,其中Q4和Q5被连接到了根节点和Q1。

在传播图上的在线聚合
在这一部分,我们描述COSMOS如何操作。在传播图上,根节点连续的扫描爬取集并缓存样本到缓冲区。图中的每个节点将会获得两种类型的数据流(其中之一可能为空)。从根节点指向查询节点的数据流提供格子空间的实际样本。两个查询节点之间的数据流传输的是聚合结果以及1型格子(完全被包含在查询中的格子)。为了减少更新成本,根节点只当缓冲区满时才向其它节点批量传送样本。当每个节点批量获得样本,它重计算它自己的聚合结果以及误差范围并更新给下游节点。新到的数据流将会对每个查询节点触发一个更新时间,并使用算法5来更新自己的结果及错误边界。

在算法5中,查询节点首先用新到的数据流更新它自己涉及到的格子。如果一个数据流是1型格子的部分结果,那么该节点只需要保留该结果的副本即可。如果数据流是从数据库来的新样本,我们需要重新计算各个格子的聚合结果(1型的和2型的)。我们将在第四部分讨论聚合计算的公式。需要注意的是,在这一步的最后,我们就有了每个格子的聚合结果以及误差范围。注意,一个查询的真正聚合结果需要合并这些部分结果。同上,我们将在第四部分套路这些结果如何合并。
在查询更新它自己的结果之后,它开始向下游节点传播自己的结果。对于一个下游节点Qi以及它注册的格子集G,对任意gi属于G,如果gi的结果已经更新,我们将gi的新结果递给节点Qi。
查询可以在以下两种情况下终止。1、查询已经扫描完了整个数据集并生成了最终准确的结果。最开始,当一个查询获得了一个格子的样本,它将标记该格子以这样本为起始页(抛锚页)。如果该格子再次看见起始页,它将停止获取样本因为它已经扫描了整个的数据集。如果查询涉及的搜索格子都停止获取样本了,那么该查询就能生成准确的结果了。此外,如果一个查询从它的上游节点获取格子的信息,它将继承该上游节点的起始页(抛锚页)信息。2、第二种情况由用户决定。当用户对结果满意时,他能够在扫描完整个数据集之前终止查询处理。
在上述讨论中,我们展示了传播图的维护策略,这个策略用于回收利用完全包含在查询中的格子的样本。如果格子只是部分的与一个查询相重合,我们必须从数据源中获取样本,令与当前查询有覆盖的格子的集合记为Sg。为了促进在Sg中的查询处理,我们为Sg中的格子维护了一个样本缓冲区。特别的是,样本源为每个在Sg中的样本保留最近k个样本。当gi收到一个新样本时,它会被插入到缓冲区中,如果缓冲区满,老的样本将会被丢弃。
给定一个新的查询Q,假设gi与Q部分重叠。当S加入到传播图时,我们检查gi在源节点的样本缓冲区。对于超出Q谓词条件的样本,我们使用其来计算gi的初始结果(为了有效的定位满足谓词的样本,我们可以使用索引结构,比如R-tree,来维护缓冲区中样本)。初始化后,gi的结果将会被来自于数据源的节点所更新。
4、统计估计
在COSMOS中,对于传播图中的每个节点/查询,有如下三种值需要估计: 1、对直接连向数据源的查询所需要的1型格子的估计 2、对2型格子的估计–这对于部分覆盖它的查询的格子的查询有需要,样本需要从数据源获取(this is needed for a query that requiresgrids that partially overlap its query region and samples haveto be drawn from the sample source) 3、对查询本身的估计–需要整合上述两种估计