VerdictDB Universalizing Approximate Query Processing
2018, Sep 02
摘要
- 近似查询处理学术研究很充裕,工业实践比较少
- 来自各数据库内部的阻力—-不想改代码!
- 近似查询的使用将迫使用户抛弃现使用的数据库—-不现实!
- 因此作者提出一种通用的解决方案—一个数据库无关近似查询处理引擎。
VERDICT基本方法
- 使AQP居于驱动层,不改变原有数据库
- 引进中间件,重写用户请求,用户请求以关系型数据库语义像数据库发送并获得其近似结果
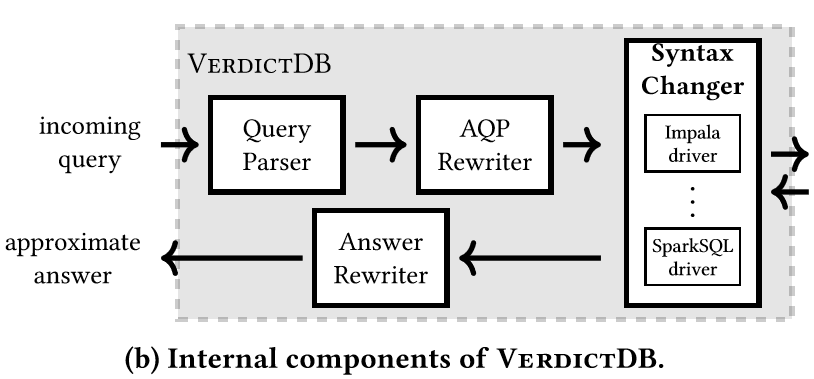
- 整个近似查询处理过程被编译成SQL形式,包括取样、近似处理以及错误估计
Challenges
- 统计正确性—其他通过外键约束、修改join算法来实现,对于中间件来说,这些方法将不再适用
- 中间件效率—中间件不能承担大量计算,因为其没有查询优化以及分布式资源
- 服务器效率—错误估计须被表达成SQL查询,这将及其昂贵并且与近似查询的初中初衷相违背
设计标准
- 提供普适性—能支持大部分的分析型需求
- 提供统计正确性—在不须访问数据库内部的前提之下,无偏近似和粗偶估计
- 保证效率—需要比一般的查询处理快得多
我们的方法
- 通过使用subsampling的理论规避了bootstrap的计算成本
- 提出一种有效计算的选择,称之为变分二次抽样
- 只依赖SQL表述来达到分层抽样的目的
系统架构
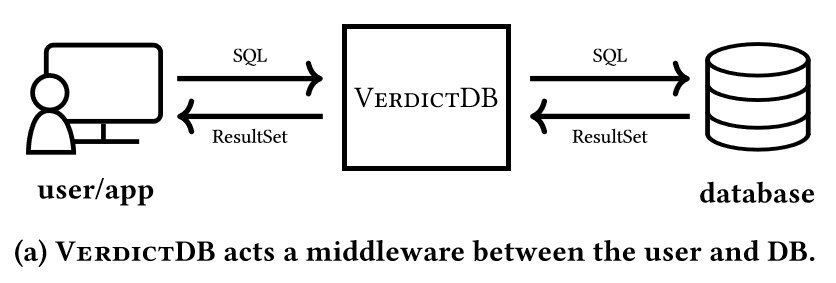
VERDICTDB内部结构
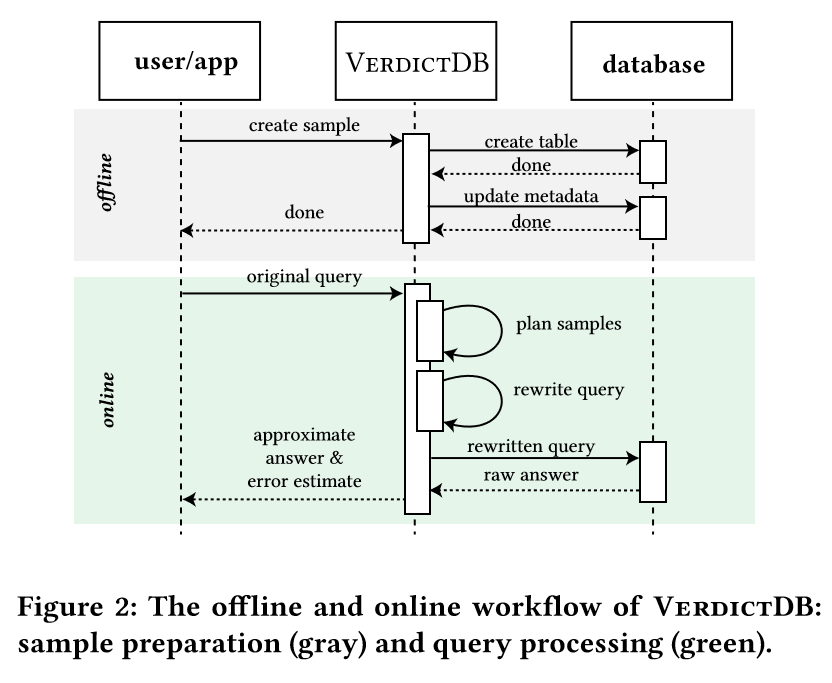
样本准备和查询处理
取样方法
- 均匀取样—每个样本都能以相同的概率被抽取到
- 哈希取样(universe取样)—不放回取样,从n个里面取m个
- 分层抽样
- 不规则取样—以上哪种都不是的取样
接下来是文章的一大重点—变分二次取样 很多公式,我也看得不是很懂,回头再慢慢深入看吧,先补补概率论知识先
总结
干货满满的一篇文章。把如何搭建一个近似查询处理系统的过程描写的非常的详细。从顶层的接口设计,到最底层的SQL编写,都写的非常认真。由浅入深,理论研究也非常的靠谱。 值得一读再读的论文!