ZooKeeper简介
ZooKeeper:一个分布式协调服务
ZooKeeper是一个分布式的,开源的分布式应用协调服务。它公开了一组简单的原语,分布式应用程序可以在这些原语的基础上实现更高级别的服务,以实现同步、配置管理、分组和命名服务。它被设计成易于编程,并且使用了一个数据模型,该数据模型采用了文件系统中常见的目录树结构。它在Java中运行,并具有Java和C的绑定。
众所周知,协调服务很难做好。它们特别容易出现诸如竞态条件和死锁之类的错误。ZooKeeper背后的动机是减轻分布式应用从零开始实现协调服务的责任。
设计目标
简单 ZooKeeper通过一个共享的类文件系统的层次命名空间,使分布式进程之间能够协调工作。命名空间由称为znode的数据登记簿组成,znode类似于文件和目录。与旨在存储的典型文件系统不同的是,ZooKeeper把数据存在内存中,这使得ZooKeeper能够拥有高吞吐量并保持低延迟。
ZooKeeper的实现非常重视高性能、高可用性和严格有序的访问。ZooKeeper的性能方面意味着它可以在大型分布式系统中使用。可靠性方面使它避免出现单点故障。严格有序意味着可以在客户机上实现复杂的同步原语。
可复制 就像它协调的分布式进程一样,ZooKeeper本身也要在一组被称为集成的主机上进行复制。
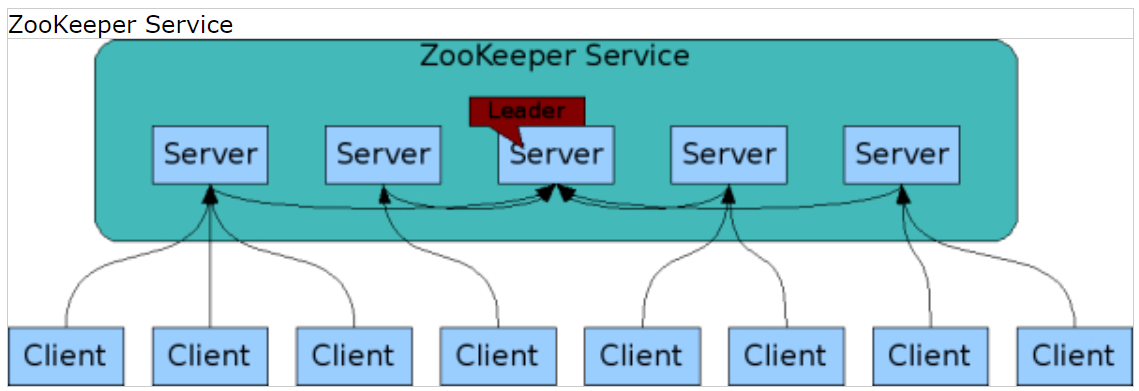
构成ZooKeeper服务的服务器必须相互了解。它们维护状态的内存映像,以及持久存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper服务就可用。
客户端连接到一个ZooKeeper服务器。客户端维护一个TCP连接,通过它发送请求、获取响应、查看事件和发送心跳。如果到服务器的TCP连接中断,客户机将连接到另一个服务器。
有序 ZooKeeper用一个反映所有ZooKeeper事务顺序的数字来标记每次更新。后续操作可以使用顺序实现更高级别的抽象,比如同步原语。
快速 它在“读为主”的工作负载中尤其快速。ZooKeeper应用程序在数千台机器上运行,在读比写更普遍的地方运行得最好,比率约为10:1。
数据模型和层次命名空间
ZooKeeper提供的名称空间很像标准文件系统。名称是由一个斜杠(/)分隔的路径元素序列。ZooKeeper的名字空间中的每个节点都由一条路径来标识。
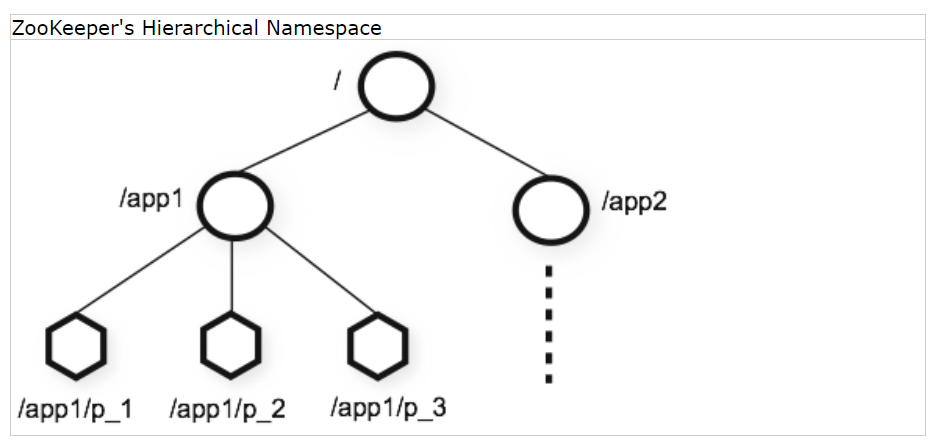
节点和临时节点 与标准文件系统不同,ZooKeeper命名空间中的每个节点都可以拥有与之关联的数据以及子节点。这就像一个文件系统,允许文件也是一个目录。(ZooKeeper被设计来存储协调数据:状态信息、配置、位置信息等,所以存储在每个节点的数据通常很小,从字节到千字节不等。)我们使用术语znode是为了说明我们讨论的是ZooKeeper数据节点。
Znodes维护一个stat结构,其中包括数据更改的版本号、ACL更改和时间戳,以允许缓存验证和协调更新。每次znode的数据发生变化,版本号就会增加。例如,每当客户机检索数据时,它也会接收数据的版本。
在命名空间中的每个znode上存储的数据是原子式读写的。读取获取与znode关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表(ACL),它限制谁可以做什么。
ZooKeeper也有临时节点的概念。只要创建znode的会话是有效的,这些znode就存在。当会话结束时,znode将被删除。当您想要实现[tbd]时,临时节点非常有用。
条件更新和监听 ZooKeeper支持监听的概念。客户端可以监听znode节点。当znode发生变化时,监听将被触发并移除。当监听被触发时,客户端会收到一个报文,说znode已经改变了。如果客户端和ZooKeeper服务器之间的连接中断,客户端将收到本地通知。这些可以用来[tbd]。
保证 ZooKeeper是非常快和非常简单。但是,由于它的目标是成为构建更复杂服务(如同步)的基础,所以它提供了一组保证:
- 顺序一致性–从客户端发出的更新将按发送顺序应用。
- 原子性–更新成功或失败。没有部分结果。
- 单一系统镜像–客户机将看到相同的服务视图,而不管它连接到哪个服务器。
- 可靠性–一旦更新被应用,它将从那个时间一直持续到被客户端重写。
- 时效性–客户端的系统视图保证在一定的时间范围内是最新的。
有关这些信息以及如何使用它们的更多信息,请参见[tbd]
Simple API
create
creates a node at a location in the tree
delete
deletes a node
exists
tests if a node exists at a location
get data
reads the data from a node
set data
writes data to a node
get children
retrieves a list of children of a node
sync
waits for data to be propagated
实现
下图显示了ZooKeeper服务的高级组件。除了请求处理器之外,构成ZooKeeper服务的每个服务器都复制自己的每个组件副本。
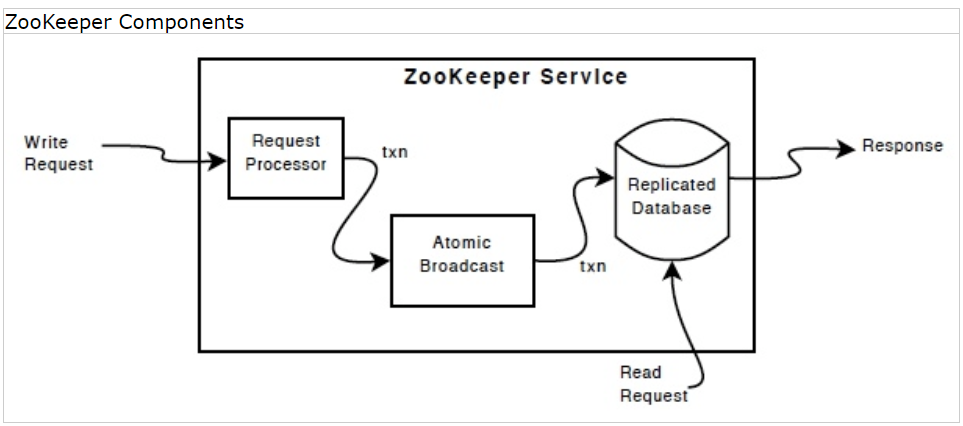
复制的数据库是包含整个数据树的内存数据库。更新被记录到磁盘以实现可恢复性,写操作在应用到内存数据库之前被序列化到磁盘。
每个ZooKeeper服务器都能够对客户端提供服务。客户机连接到一个服务器以提交请求。读取请求从每个服务器数据库的本地副本进行服务。更改服务状态的请求,写请求,是通过一个协同协议来处理的。
作为协同协议的一部分,所有来自客户机的写请求都被转发到一个名为leader的服务器。其他的ZooKeeper服务器,被称为followers,接收来自leader的消息提议并同意消息传递。消息传递层负责在失败时替换leader,并将followers与leader同步。
ZooKeeper使用自定义原子消息传递协议。由于消息传递层是原子层,ZooKeeper可以确保本地副本不会分散。当leader收到写请求时,它会计算应用写时系统的状态,并将其转换为捕获新状态的事务。