一、概览
1、Collection
List
- ArrayList
- LinkedList
- Vector(了解,已过时)
Set
- HashSet
- LinkedHashSet
- TreeSet
2、Map
HashMap
- LinkedHashMap
TreeMap
ConcurrentHashMap
HashTable(了解,已过时)
二、Collection
1、什么是java集合类?
- Java集合框架为程序员提供了预先包装的数据结构和算法来操纵他们。
- 集合是一个对象,可容纳其他对象的引用。集合接口声明对每一种类型的集合可以执行的操作。
- 集合框架的类和接口均在java.util包中。
- 任何对象加入集合类后,自动转变为Object类型,所以在取出的时候,需要进行强制类型转换。
2、数组和集合的区别
- 数组的长度固定、集合的长度可变
- 数组可以存基本数据类型,也可以存储引用类型,集合只能存储引用类型
3、Collection和Collections的区别
Collection是接口,Collections是工具类
三、迭代器
迭代器模式(Iterator),提供一种方法顺序访问一个聚合对象中的各种元素,而又不暴露该对象的内部表示。
Iterator也是一个接口,它只有三个方法:
- hasNext()
- next()
- remove()
四、List集合
List集合的特点就是:有序(存储顺序和取出顺序一致),可重复
List集合常用的子类有三个:
- ArrayList:底层数据结构是数组。线程不安全
- LinkedList:底层数据结构是链表。线程不安全
- Vector:底层数据结构是数组。线程安全
五、Set集合
Set集合的特点是:元素不可重复
Set集合常用的子类:
- HashSet集合:底层数据结构是HashMap(是一个元素为链表的数组)
- TreeSet集合:底层数据结构是红黑树(是一个自平衡的二叉树),保证元素的排序方式
- LinkedHashSet集合:底层数据结构由LinkedHashMap
五、ArrayList源码分析
底层是数组
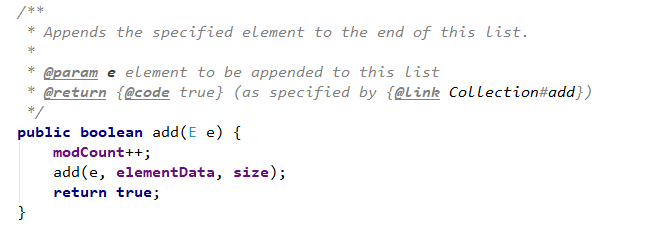
添加元素
添加元素到指定索引,先检查是否越界,然后检查容量是否足够,不够的话,扩容,然后把index后面的元素往后移一位
扩容


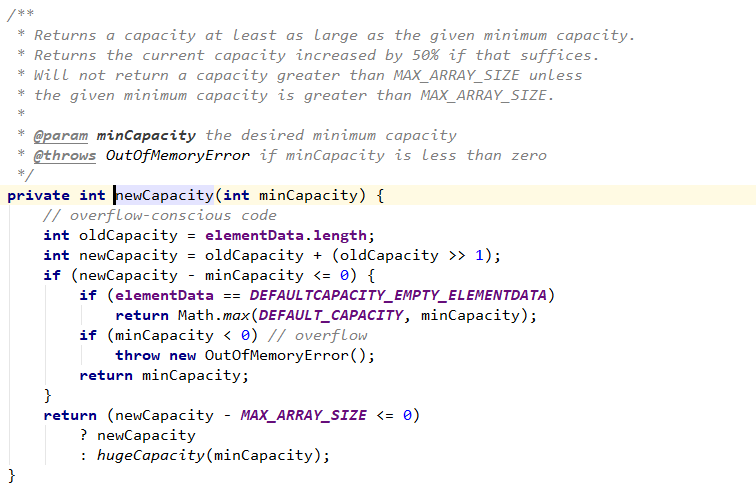
默认是扩为原来容量的1.5倍
总结
- ArrayList是基于动态数组实现的,在增删时候,需要数组的拷贝复制。
- ArrayList的默认初始化容量是10,每次扩容时候增加原先容量的一半,也就是变为原来的1.5倍
- 删除元素时不会减少容量,若希望减少容量则调用trimToSize()
- 它不是线程安全的。它能存放null值。
Vector与ArrayList区别
- Vector底层也是数组,但是线程安全,实现方式为每个方法加synchronized关键字
- ArrayList在底层数组不够用时在原来的基础上扩展0.5倍,Vector是扩展1倍。
LinkedList
底层是双向链表,同时还实现了Deque接口,所以可以当做队列使用。
六、Map
Map即键值对,通过key,找到value
散列表
散列表为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在对应的位置上!
在Java中,散列表用的是链表数组实现的,每个列表称之为桶。
一个桶上可能会遇到被占用的情况(hashCode散列码相同,就存储在同一个位置上),这种情况是无法避免的,这种现象称之为:散列冲突
- 此时需要用该对象与桶上的对象进行比较,看看该对象是否存在桶子上了~如果存在,就不添加了,如果不存在则添加到桶子上。
- 当然了,如果hashcode函数设计得足够好,桶的数目也足够,这种比较是很少的~
- 在JDK1.8中,桶满时会从链表变成特殊的平衡二叉树(红黑树)
如果散列表太满,是需要对散列表再散列,创建一个桶数更多的散列表,并将原有的元素插入到新表中,丢弃原来的表~
- 装填因子(load factor)决定了何时对散列表再散列~
- 装填因子默认为0.75,如果表中超过了75%的位置已经填入了元素,那么这个表就会用双倍的桶数自动进行再散列
红黑树
红黑树是在2-3的基础上实现的一种树,它能够用统一的方式完成所有变换。
红黑树用的是也是两种方式来替代2-3树不断的节点交换操作:
- 旋转:顺时针旋转和逆时针旋转
- 反色:交换红黑的颜色
红黑树的定义
- 红黑树是二叉搜索树。
- 根节点是黑色。
- 每个叶子节点都是黑色的空节点(NIL节点)。
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点(每一条树链上的黑色节点数量(称之为“黑高”)必须相等)。
HashMap
- 无序,HashMap最多只允许一条记录的键为null,允许多条记录的值为null,非线程安全
- 底层由散列表(哈希表)实现,数组加链表,当链表长度大于8(测试出来的)时,转换成一棵红黑树,当树的大小小于6时,转换成链表
- 初始容量(默认16)和装载因子(默认0.75)对HashMap影响挺大的,设置小了不好,设置大了也不好
- 哈希表的size要至少为64才能构造红黑树,否则应该扩容再散列来防止一个桶里有过多的节点。
LinkedHashMap
- LinkedHashMap比HashMap多了一个双向链表的维护,但是很多操作都是基于HashMap的。
- 能够保证插入元素的顺序。
ConcurrentHashMap
- 其他实现类似于HashMap,包括什么时候把链表扩展成红黑树等
- 当头结点为空时,使用CAS机制插入,若冲突了,插入不成功,返回null
- 头结点不为空时,锁头(synchronized)
- get方法不加锁,Node结点是重写的,设置了volatile关键字,致使每次获取的都是最新设置的值
- ConcurrentHashMap的key和Value都不能为null
七、Set集合
HashSet集合
- A:底层数据结构是HashMap,所有的value指向同一个冗余的Object
TreeSet集合
- A:底层数据结构是红黑树(是一个自平衡的二叉树)
- B:保证元素的排序方式
- 底层实际上是一个TreeMap实例
LinkedHashSet集合
- A:底层数据结构由LinkedHashMap